Journals > > Topics > Image Processing
Image Processing|479 Article(s)

Study on Gray Level Residual Field Calculation in Digital Volume Correlation
Bing Pan, Xuanhao Zhang, and Long Wang
ObjectiveGray level residual (GLR) field refers to the intensity differences between corresponding voxel points in the digital volume images acquired before and after deformation. Typically, internal damage in materials induces substantial variations in grayscale values between corresponding voxel points. Therefore, the GLR field helps to reveal the damage location. In the finite element-based global digital volume correlation (DVC) method, the GLR field, as the matching quality evaluation criteria, can be readily calculated and has been employed to characterize the evolution of internal cracks. However, the widely used subvolume-based local DVC, which can output displacement, strain, and correlation coefficient at discrete calculation points, cannot obtain the GLR directly. Compared with correlation coefficient and deformation information, the GLR field achieves voxelwise matching quality evaluation, thus demonstrating superior performance in visualizing internal damage. Therefore, accurate GLR calculation in local DVC is undoubtedly valuable in compensating for its shortcomings in fine-matching quality evaluation and expanding its applications in internal damage observation and localization.MethodsThe GLR field is obtained by subtracting the reference volume image from the deformed volume image after full-field correction. The key of its calculation is to utilize the continuous voxelwise data, including contrast and brightness correction coefficients and displacement, to correct the deformed volume image. In this work, a dense interpolation algorithm based on finite element mesh is adopted to estimate the voxelwise data within the volume of interest (VOI). 3D Delaunay triangulation algorithm is first utilized to generate tetrahedron element mesh from the discrete calculation points, and then the data of voxel points inside each tetrahedron element can be determined with the shape function of finite element. After acquiring the voxel-wise data of VOI within the reference volume image, the corrected deformed volume image can be reconstructed. Given that the corresponding voxel points in the deformed volume image normally fall into the subvoxel positions, a subvoxel intensity interpolation scheme is required during the calculation of correlation residual in local DVC. In this work, the advanced cubic B-spline interpolation method is adopted to estimate the grayscale of the corrected deformed volume image. In addition, a simulated mode I crack test and a tensile test of nodular cast iron are carried out to verify the feasibility of the GLR field based on local DVC and the reliability and robustness in damage observation and detection.Results and DiscussionsIn simulated mode I crack test, the results show that the uncorrected GLR field still keeps a higher grayscale even in the region away from the crack compared with the corrected GLR field (Fig. 7), which degrades the damage observation and location. Therefore, contrast and brightness correction are necessary during the calculation of the GLR field. The crack plane can be detected clearly from the GLR field after threshold processing, and the position of the crack plane is very close to the preset value (Fig. 7). The proposed GLR based on local DVC effectively eliminates the influence of contrast and brightness changes and achieves precise crack location. Additionally, more information about the damage can be acquired from the GLR field. The crack morphology and orientation can be determined from the slice image at y=40 voxel in the real test. Besides, the debonding between the nodular graphite and matrix can also be detected roughly from the GLR field (Fig. 10). It should be noted that the GLR field after post-processing can only reflect the approximate morphology of damages and fails to reflect the opening of crack and debonding accurately since the interpolation used in displacement correlation may enlarge the region with damage. Despite all this, the location and morphology of damages extracted from the GLR field are helpful in understanding the fracture mechanics properties of nodular graphite cast iron.ConclusionsA simple and practical method for GLR field calculation based on post-processing of local DVC measurements is proposed. The method addresses the limitations of existing local DVC in fine-matching quality evaluation. Compared with correlation coefficient and deformation information, the GLR field not only accurately reflects the location of internal damage but also facilitates visual observation of internal crack morphology and interface debonding behavior. It holds the potential for broader applications in visualizing and precisely locating internal damage within materials and structures. ObjectiveGray level residual (GLR) field refers to the intensity differences between corresponding voxel points in the digital volume images acquired before and after deformation. Typically, internal damage in materials induces substantial variations in grayscale values between corresponding voxel points. Therefore, the GLR field helps to reveal the damage location. In the finite element-based global digital volume correlation (DVC) method, the GLR field, as the matching quality evaluation criteria, can be readily calculated and has been employed to characterize the evolution of internal cracks. However, the widely used subvolume-based local DVC, which can output displacement, strain, and correlation coefficient at discrete calculation points, cannot obtain the GLR directly. Compared with correlation coefficient and deformation information, the GLR field achieves voxelwise matching quality evaluation, thus demonstrating superior performance in visualizing internal damage. Therefore, accurate GLR calculation in local DVC is undoubtedly valuable in compensating for its shortcomings in fine-matching quality evaluation and expanding its applications in internal damage observation and localization.MethodsThe GLR field is obtained by subtracting the reference volume image from the deformed volume image after full-field correction. The key of its calculation is to utilize the continuous voxelwise data, including contrast and brightness correction coefficients and displacement, to correct the deformed volume image. In this work, a dense interpolation algorithm based on finite element mesh is adopted to estimate the voxelwise data within the volume of interest (VOI). 3D Delaunay triangulation algorithm is first utilized to generate tetrahedron element mesh from the discrete calculation points, and then the data of voxel points inside each tetrahedron element can be determined with the shape function of finite element. After acquiring the voxel-wise data of VOI within the reference volume image, the corrected deformed volume image can be reconstructed. Given that the corresponding voxel points in the deformed volume image normally fall into the subvoxel positions, a subvoxel intensity interpolation scheme is required during the calculation of correlation residual in local DVC. In this work, the advanced cubic B-spline interpolation method is adopted to estimate the grayscale of the corrected deformed volume image. In addition, a simulated mode I crack test and a tensile test of nodular cast iron are carried out to verify the feasibility of the GLR field based on local DVC and the reliability and robustness in damage observation and detection.Results and DiscussionsIn simulated mode I crack test, the results show that the uncorrected GLR field still keeps a higher grayscale even in the region away from the crack compared with the corrected GLR field (Fig. 7), which degrades the damage observation and location. Therefore, contrast and brightness correction are necessary during the calculation of the GLR field. The crack plane can be detected clearly from the GLR field after threshold processing, and the position of the crack plane is very close to the preset value (Fig. 7). The proposed GLR based on local DVC effectively eliminates the influence of contrast and brightness changes and achieves precise crack location. Additionally, more information about the damage can be acquired from the GLR field. The crack morphology and orientation can be determined from the slice image at y=40 voxel in the real test. Besides, the debonding between the nodular graphite and matrix can also be detected roughly from the GLR field (Fig. 10). It should be noted that the GLR field after post-processing can only reflect the approximate morphology of damages and fails to reflect the opening of crack and debonding accurately since the interpolation used in displacement correlation may enlarge the region with damage. Despite all this, the location and morphology of damages extracted from the GLR field are helpful in understanding the fracture mechanics properties of nodular graphite cast iron.ConclusionsA simple and practical method for GLR field calculation based on post-processing of local DVC measurements is proposed. The method addresses the limitations of existing local DVC in fine-matching quality evaluation. Compared with correlation coefficient and deformation information, the GLR field not only accurately reflects the location of internal damage but also facilitates visual observation of internal crack morphology and interface debonding behavior. It holds the potential for broader applications in visualizing and precisely locating internal damage within materials and structures.
Acta Optica Sinica
- Publication Date: Feb. 10, 2024
- Vol. 44, Issue 3, 0310001 (2024)

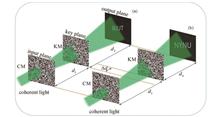
Position-Multiplexing-Based Double-Image Encryption in Cascaded Double-Phase Encoding Cryptosystem
Yi Qin, Yuhong Wan, and Qiong Gong
ObjectiveCascaded double-phase encoding (CDPE) is an optical cryptosystem, and it comprises two phase-only masks (ciphertext mask and key mask). Among optical cryptosystems, CDPE is of great importance due to its superiority in security. Its ciphertext is a phase-only mask whose content cannot be directly read out by the intensity-sensitive device such as the charge-coupled device (CCD) or human eyes. Although there is already published research on CDPE, few of them focus on simultaneous compression and encryption. In this paper, we propose a novel iterative encryption algorithm (IEA) to achieve double-image encryption in CDPE, which employs the position of the key mask as a controllable parameter. Compared with that of the traditional CDPE, the encryption capacity of the proposed algorithm has been substantially improved. The proposed algorithm opens up a new way for simultaneous compression and encryption in CDPE, and it may offer new inspiration for the design of other cryptosystems.MethodsThe optical architecture for decryption in this paper comprises two phase-only masks (ciphertext mask and key mask). Parallel monochromatic light is employed for illumination. The positions of the ciphertext mask and the output plane are fixed during decryption. Two positions along the axis are specified for the key mask. When the key mask locates respectively at these positions, two distinct plaintexts can be individually generated at the output plane. Essentially, the decryption employs two different optical architectures which differ only in the position of the key mask. According to the decryption principle, an IEA is proposed to encrypt the two plaintexts into the ciphertext mask. The IEA requires parallel iteration in the two optical architectures. For each architecture, the light wave virtually illuminates the scheme and finally reaches the output plane after being modulated by the two phase-only masks. At the output plane, the amplitude of the wavefront is replaced with the plaintext. The renewed wavefront at the output plane then propagates back to the input plane and forms a complex amplitude. The two complex amplitudes from the two architectures are superposed and then phase-reserved to obtain a new estimation of the ciphertext mask. The first iteration completes after the update of the ciphertext mask, and then the second iteration begins. The iteration will continue until the decrypted plaintexts at the output plane sufficiently approximate the original ones.Results and DiscussionsFirst, we validate the effectiveness of the proposed algorithm with binary images in the simulation context of MATLAB R2016a. The proposed IEA shows excellent convergence, and it terminates after 238 iterations. Both the subjective and objective metrics indicate the high quality of decrypted plaintexts (Fig. 3), which verifies the effectiveness of the proposed algorithm. Second, we analyze the key space created by each of the secret keys, including the wavelength, axial distances, and key mask. The key space of the proposed algorithm is as large as 2104856, which is robust enough to resist brute-force attacks. Third, we investigate the condition for successful multiplexing. The results show that a minimum position interval of 2 mm of the key mask is required (Fig. 7), and an interval exceeding this value will cause obvious cross-talk noise in the decrypted images. Fourth, we verify the proposed algorithm with grayscale images and successfully extend it to multiple-image encryption (Fig. 8 and Fig. 9). The corresponding results show that the quality of the decrypted images decays with the image number for multiplexing. Therefore, there must be a compromise between the encryption capacity and the quality of decryption. Fifth, we test the robustness of the proposed algorithm against noise attacks, and the results show that the ciphertext can still ensure high-quality decryption in spite of severe contamination (Fig. 10). Sixth, we analyze the robustness of the proposed algorithm to cryptoanalysis. It is found that a chosen-plaintext attack (CPA) based on the G-S algorithm fails to crack the proposed algorithm (Fig. 11). Seventh, we further demonstrate the effectiveness of the proposed algorithm with experimental results (Fig. 13 and Fig. 14), which highly agree with the simulated ones.ConclusionsIn this paper, a double-image encryption method based on position-multiplexing in the CDPE system is proposed. A new IEA is presented to encrypt two plaintext images into a single phase-only mask (ciphertext mask). Compared with that of the traditional CDPE, the encryption capacity of this method is doubled. For decryption, the key mask is placed respectively at two preset axial positions, and two different plaintext images can be individually obtained at the same output plane. In addition, for successful position multiplexing to avoid crosstalk, the distance between the two axial positions of the key mask must be greater than a certain value. The security analysis shows that the proposed algorithm has a huge key space that is enough to resist brute-force attacks. Furthermore, the G-S algorithm is adopted to provide a CPA to the proposed algorithm, and the results show that the proposed algorithm is robust to the CPA. In addition, the feasibility of extending the proposed algorithm to multiple-image encryption is proven, which indicates that the encryption efficiency of CDPE systems can be further enhanced. ObjectiveCascaded double-phase encoding (CDPE) is an optical cryptosystem, and it comprises two phase-only masks (ciphertext mask and key mask). Among optical cryptosystems, CDPE is of great importance due to its superiority in security. Its ciphertext is a phase-only mask whose content cannot be directly read out by the intensity-sensitive device such as the charge-coupled device (CCD) or human eyes. Although there is already published research on CDPE, few of them focus on simultaneous compression and encryption. In this paper, we propose a novel iterative encryption algorithm (IEA) to achieve double-image encryption in CDPE, which employs the position of the key mask as a controllable parameter. Compared with that of the traditional CDPE, the encryption capacity of the proposed algorithm has been substantially improved. The proposed algorithm opens up a new way for simultaneous compression and encryption in CDPE, and it may offer new inspiration for the design of other cryptosystems.MethodsThe optical architecture for decryption in this paper comprises two phase-only masks (ciphertext mask and key mask). Parallel monochromatic light is employed for illumination. The positions of the ciphertext mask and the output plane are fixed during decryption. Two positions along the axis are specified for the key mask. When the key mask locates respectively at these positions, two distinct plaintexts can be individually generated at the output plane. Essentially, the decryption employs two different optical architectures which differ only in the position of the key mask. According to the decryption principle, an IEA is proposed to encrypt the two plaintexts into the ciphertext mask. The IEA requires parallel iteration in the two optical architectures. For each architecture, the light wave virtually illuminates the scheme and finally reaches the output plane after being modulated by the two phase-only masks. At the output plane, the amplitude of the wavefront is replaced with the plaintext. The renewed wavefront at the output plane then propagates back to the input plane and forms a complex amplitude. The two complex amplitudes from the two architectures are superposed and then phase-reserved to obtain a new estimation of the ciphertext mask. The first iteration completes after the update of the ciphertext mask, and then the second iteration begins. The iteration will continue until the decrypted plaintexts at the output plane sufficiently approximate the original ones.Results and DiscussionsFirst, we validate the effectiveness of the proposed algorithm with binary images in the simulation context of MATLAB R2016a. The proposed IEA shows excellent convergence, and it terminates after 238 iterations. Both the subjective and objective metrics indicate the high quality of decrypted plaintexts (Fig. 3), which verifies the effectiveness of the proposed algorithm. Second, we analyze the key space created by each of the secret keys, including the wavelength, axial distances, and key mask. The key space of the proposed algorithm is as large as 2104856, which is robust enough to resist brute-force attacks. Third, we investigate the condition for successful multiplexing. The results show that a minimum position interval of 2 mm of the key mask is required (Fig. 7), and an interval exceeding this value will cause obvious cross-talk noise in the decrypted images. Fourth, we verify the proposed algorithm with grayscale images and successfully extend it to multiple-image encryption (Fig. 8 and Fig. 9). The corresponding results show that the quality of the decrypted images decays with the image number for multiplexing. Therefore, there must be a compromise between the encryption capacity and the quality of decryption. Fifth, we test the robustness of the proposed algorithm against noise attacks, and the results show that the ciphertext can still ensure high-quality decryption in spite of severe contamination (Fig. 10). Sixth, we analyze the robustness of the proposed algorithm to cryptoanalysis. It is found that a chosen-plaintext attack (CPA) based on the G-S algorithm fails to crack the proposed algorithm (Fig. 11). Seventh, we further demonstrate the effectiveness of the proposed algorithm with experimental results (Fig. 13 and Fig. 14), which highly agree with the simulated ones.ConclusionsIn this paper, a double-image encryption method based on position-multiplexing in the CDPE system is proposed. A new IEA is presented to encrypt two plaintext images into a single phase-only mask (ciphertext mask). Compared with that of the traditional CDPE, the encryption capacity of this method is doubled. For decryption, the key mask is placed respectively at two preset axial positions, and two different plaintext images can be individually obtained at the same output plane. In addition, for successful position multiplexing to avoid crosstalk, the distance between the two axial positions of the key mask must be greater than a certain value. The security analysis shows that the proposed algorithm has a huge key space that is enough to resist brute-force attacks. Furthermore, the G-S algorithm is adopted to provide a CPA to the proposed algorithm, and the results show that the proposed algorithm is robust to the CPA. In addition, the feasibility of extending the proposed algorithm to multiple-image encryption is proven, which indicates that the encryption efficiency of CDPE systems can be further enhanced.
Acta Optica Sinica
- Publication Date: May. 10, 2023
- Vol. 43, Issue 9, 0910001 (2023)
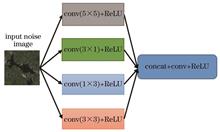
Synthetic Aperture Radar Image Denoising Algorithm Based on Deep Learning
Xiangwei Fu, Huilin Shan, Lü Zongkui, and Xingtao Wang
ObjectiveSynthetic aperture radar (SAR) is a kind of sensor to capture microwaves. Its principle is to establish images through the reflection of waveforms, so as to solve the problem that traditional optical remote sensing radars are affected by weather, air impurities, and other environmental factors when collecting images. The most widely used SAR is change detection (CD). CD refers to the dynamic acquisition of image information from a certain target, which includes three steps: image preprocessing, generation of difference maps, and analysis and calculation of difference maps. It is applied to the estimation of natural disasters, management and allocation of resources, and measurement of land topographic characteristics. However, in the process of CD, the inherent speckle noise in SAR images will reduce the performance of CD. Therefore, the image denoising method has become a basic method of preprocessing in CD. How to restore a clean image from a noisy SAR image is an urgent problem to be solved.MethodsTraditional denoising algorithms of SAR images generally use the global denoising idea whose principle is to use the global similar information in images to perform processing and judgment. In the case of the high resolution of images, these algorithms need a series of preprocessing such as smoothing and then complete pixel distinction through the neighborhood processing of each image block. The algorithms usually occupy huge computing resources and have certain spatial and temporal limitations in practical applications. In addition, they cannot efficiently complete the denoising task. In terms of deep learning, some algorithms perform well, but there is still room for improvement in network convergence speed, model redundancy, and accuracy. To solve these problems, this paper proposes a denoising algorithm based on a multi-scale attention cascade convolutional neural network (MALNet). The network mainly uses the idea of multi-scale irregular convolution kernel and attention. Compared with a single convolution kernel, a multi-scale irregular convolution kernel has an excellent image receptive field. In other words, it can collect image information from different scales to extract more detailed image features. Subsequently, the convolution kernels of different scales are concat layers in the network, and an attention mechanism is introduced into a concat feature map to divide the attention of the features so that the whole model has a positive enhancement ability for the main features of the image. In the middle of the network, the dense cascade layer is used to further strengthen the features. Finally, the image restoration and reconstruction are realized by network subtraction.Results and DiscussionsIn this paper, qualitative and quantitative experiments are carried out to evaluate and demonstrate the performance of the proposed MALNet model in denoising. The WNNM, SAR-BM3D, and SAR-CNN algorithms are compared with our proposed method. The clear state and complete signs of the denoised images are visually observed. In order to make a fair comparison, we use the default settings of the three algorithms provided by the authors in the literatures. Peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and image entropy are used as objective evaluation indexes. The PSNR, SSIM, and image entropy are calculated as error metrics.Three denoising algorithms are compared, and airpoirt, mountain, and coast are selected as verification images. The denoising effects of airport images (Fig. 7), coast images (Fig. 8), and mountain images (Fig. 9) are analyzed. It shows the visual effect comparison of denoising results of different algorithms. In Figs. 7-9, 6 figures are successively noise-free image, noise image, denoised image obtained by WNNM, denoised image obtained by SAR-BM3D, denoised image obtained by SAR-CNN and denoised image obtained by MALNet. It is obvious that the WNNM denoised image has many defects that are not removed completely, and the texture loss is quite serious. SAR-BM3D denoised image retains some details, but the aircraft fuselage is very vague, and the tail part has gotten most of the edge information erased. Although the aircraft wing in the SAR-CNN denoised image is recovered, the whole aircraft at the bottom is still far from the reference image, and the recovered small objects are blurred.It can be seen from Table 3 that the average PSNR value of the proposed MALNet is about 9.25 dB higher than that of SAR-BM3D, about 0.75 dB higher than that of SAR-CNN, and about 14.45 dB higher than that of WNNM. Moreover, in terms of the noise level, MALNet is 0.01 dB less than that SAR-CNN. The PSNR value of the proposed MALNet model at each noise level is higher than that of other algorithms. Especially, when the noise parameter is 20, the proposed method is 2.56 dB higher than that of the SAR-CNN algorithm. In terms of structural similarity (Table 4), it can be seen that the SSIM of MALNet is mostly the highest among all methods. Only when the noise parameter is 50, it is slightly lower than that of SAR-CNN, but the average SSIM is still the highest. The average information entropy of the denoised images by the four algorithms is 7.113492 bit/pixel for WNNM, 6.842258 bit/pixel for SAR-BM3D, 7.499375 bit/pixel for SAR-CNN, and 6.6917 bit/pixel for MALNet. The proposed algorithm outperforms WNNM, SAR-BM3D, and SAR-CNN by 0.42179 bit/pixel, 0.15056 bit/pixel, and 0.80768 bit/pixel, respectively. Therefore, in terms of the three objective evaluation indexes of PSNR, SSIM, and image entropy, the proposed network in this paper has better denoising performance than other comparison methods.ConclusionsIn this paper, a new denoising model MALNet is proposed for solving the noise in SAR images. This model uses an end-to-end architecture and does not require separate subnets or manual intervention. The solution includes three modules, i.e., multi-scale irregular convolution module, feature extraction module based on attention mechanism, and feature enhancement module based on dense cascade network. The model also adds batch normalization and global average pooling to improve its adaptability. It can complete convergence without massive data sets. The image data can complete convergence after 150 rounds of training. The training efficiency is outstanding, and the portability is positive. The experimental results show that compared with those of other traditional image denoising algorithms, the PSNR and SSIM of the proposed algorithm are improved by 0.75 dB-14.45 dB and 0.01-0.16, respectively. The proposed algorithm is superior to other algorithms in image entropy and can better recover the details of images. ObjectiveSynthetic aperture radar (SAR) is a kind of sensor to capture microwaves. Its principle is to establish images through the reflection of waveforms, so as to solve the problem that traditional optical remote sensing radars are affected by weather, air impurities, and other environmental factors when collecting images. The most widely used SAR is change detection (CD). CD refers to the dynamic acquisition of image information from a certain target, which includes three steps: image preprocessing, generation of difference maps, and analysis and calculation of difference maps. It is applied to the estimation of natural disasters, management and allocation of resources, and measurement of land topographic characteristics. However, in the process of CD, the inherent speckle noise in SAR images will reduce the performance of CD. Therefore, the image denoising method has become a basic method of preprocessing in CD. How to restore a clean image from a noisy SAR image is an urgent problem to be solved.MethodsTraditional denoising algorithms of SAR images generally use the global denoising idea whose principle is to use the global similar information in images to perform processing and judgment. In the case of the high resolution of images, these algorithms need a series of preprocessing such as smoothing and then complete pixel distinction through the neighborhood processing of each image block. The algorithms usually occupy huge computing resources and have certain spatial and temporal limitations in practical applications. In addition, they cannot efficiently complete the denoising task. In terms of deep learning, some algorithms perform well, but there is still room for improvement in network convergence speed, model redundancy, and accuracy. To solve these problems, this paper proposes a denoising algorithm based on a multi-scale attention cascade convolutional neural network (MALNet). The network mainly uses the idea of multi-scale irregular convolution kernel and attention. Compared with a single convolution kernel, a multi-scale irregular convolution kernel has an excellent image receptive field. In other words, it can collect image information from different scales to extract more detailed image features. Subsequently, the convolution kernels of different scales are concat layers in the network, and an attention mechanism is introduced into a concat feature map to divide the attention of the features so that the whole model has a positive enhancement ability for the main features of the image. In the middle of the network, the dense cascade layer is used to further strengthen the features. Finally, the image restoration and reconstruction are realized by network subtraction.Results and DiscussionsIn this paper, qualitative and quantitative experiments are carried out to evaluate and demonstrate the performance of the proposed MALNet model in denoising. The WNNM, SAR-BM3D, and SAR-CNN algorithms are compared with our proposed method. The clear state and complete signs of the denoised images are visually observed. In order to make a fair comparison, we use the default settings of the three algorithms provided by the authors in the literatures. Peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and image entropy are used as objective evaluation indexes. The PSNR, SSIM, and image entropy are calculated as error metrics.Three denoising algorithms are compared, and airpoirt, mountain, and coast are selected as verification images. The denoising effects of airport images (Fig. 7), coast images (Fig. 8), and mountain images (Fig. 9) are analyzed. It shows the visual effect comparison of denoising results of different algorithms. In Figs. 7-9, 6 figures are successively noise-free image, noise image, denoised image obtained by WNNM, denoised image obtained by SAR-BM3D, denoised image obtained by SAR-CNN and denoised image obtained by MALNet. It is obvious that the WNNM denoised image has many defects that are not removed completely, and the texture loss is quite serious. SAR-BM3D denoised image retains some details, but the aircraft fuselage is very vague, and the tail part has gotten most of the edge information erased. Although the aircraft wing in the SAR-CNN denoised image is recovered, the whole aircraft at the bottom is still far from the reference image, and the recovered small objects are blurred.It can be seen from Table 3 that the average PSNR value of the proposed MALNet is about 9.25 dB higher than that of SAR-BM3D, about 0.75 dB higher than that of SAR-CNN, and about 14.45 dB higher than that of WNNM. Moreover, in terms of the noise level, MALNet is 0.01 dB less than that SAR-CNN. The PSNR value of the proposed MALNet model at each noise level is higher than that of other algorithms. Especially, when the noise parameter is 20, the proposed method is 2.56 dB higher than that of the SAR-CNN algorithm. In terms of structural similarity (Table 4), it can be seen that the SSIM of MALNet is mostly the highest among all methods. Only when the noise parameter is 50, it is slightly lower than that of SAR-CNN, but the average SSIM is still the highest. The average information entropy of the denoised images by the four algorithms is 7.113492 bit/pixel for WNNM, 6.842258 bit/pixel for SAR-BM3D, 7.499375 bit/pixel for SAR-CNN, and 6.6917 bit/pixel for MALNet. The proposed algorithm outperforms WNNM, SAR-BM3D, and SAR-CNN by 0.42179 bit/pixel, 0.15056 bit/pixel, and 0.80768 bit/pixel, respectively. Therefore, in terms of the three objective evaluation indexes of PSNR, SSIM, and image entropy, the proposed network in this paper has better denoising performance than other comparison methods.ConclusionsIn this paper, a new denoising model MALNet is proposed for solving the noise in SAR images. This model uses an end-to-end architecture and does not require separate subnets or manual intervention. The solution includes three modules, i.e., multi-scale irregular convolution module, feature extraction module based on attention mechanism, and feature enhancement module based on dense cascade network. The model also adds batch normalization and global average pooling to improve its adaptability. It can complete convergence without massive data sets. The image data can complete convergence after 150 rounds of training. The training efficiency is outstanding, and the portability is positive. The experimental results show that compared with those of other traditional image denoising algorithms, the PSNR and SSIM of the proposed algorithm are improved by 0.75 dB-14.45 dB and 0.01-0.16, respectively. The proposed algorithm is superior to other algorithms in image entropy and can better recover the details of images.
Acta Optica Sinica
- Publication Date: Mar. 25, 2023
- Vol. 43, Issue 6, 0610002 (2023)
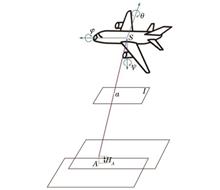
Sharpness Detection Method for Aerial Camera Images Based on Digital Elevation Model
Dongchen Dai, Lina Zheng, Yu Zhang, Haijiang Wang, Qi Kang, and Yang Zhang
ObjectiveThe working environment of aerial cameras is complex. In the process of acquiring aerial remote sensing images, the optical system is defocused due to the influence of external environments such as ground elevation difference, temperature, and air pressure. The obtained aerial remote sensing images are not clear enough. The sharpness detection methods based on image processing complete the sharpness detection through the spectrum analysis of high-frequency information in aerial remote sensing images. Taking advantage of the fast running speed of computers, the sharpness detection of aerial remote sensing images is completed in real time. Therefore, it has become the main method of sharpness detection both in China and abroad. However, the weak characteristic areas such as oceans, grasslands, and deserts, which cover more than half of the earth, have less high-frequency information in aerial remote sensing images. When using conventional image methods for sharpness detection, the error rate is high. According to the characteristics of overlapping areas between the two images, a method of aerial camera image sharpness detection based on a digital elevation model (DEM) is proposed. This method introduces a high-precision DEM, and according to the acquired weak characteristic areas, the two images before and after the aerial remote image sensing feature overlapping areas. The aerial imaging model is modified by minimizing the re-projection error, and the sharpness is detected according to the offset of feature points in the weak characteristic overlapping areas. It makes up for the defect that the sharpness detection methods based on image processing can't detect the sharpness in weak characteristic areas and expands the applicability of the sharpness detection methods based on image processing.MethodsIn this study, an aerial imaging model and feature point matching are used to obtain image sharpness parameters. Firstly, a DEM is used to provide the elevation data of the ground object in the aerial imaging model. The sum of the re-projection error of each pixel in the overlapping areas is regarded as the re-projection error function. By minimizing the re-projection error, relative error coefficients of various influencing factors can be obtained, so as to modify the aerial imaging model. Then, according to the characteristics of the overlapping areas between the two images, the geographical information of sceneries in the overlapping areas is regarded as public knowledge. The modified aerial imaging model is used to realize the feature point matching algorithm. In addition, according to the error between the feature matching points and the scale-invariant feature transformation (SIFT) algorithm matching points, the change in the azimuth elements in the aerial camera is calculated. Finally, the change in the principal distance is used as the sharpness detection result. Through the focal plane driving device of the aerial camera, the focal plane of the aerial camera can be quickly adjusted to an appropriate position, so as to obtain aerial remote sensing images with sufficient sharpness.Results and DiscussionsIn the experiment, aerial remote sensing images of the weak characteristic areas obtained by the aerial camera are transmitted to an image processing computer, and the DEM images with the accuracy of millimeter level processed by the computer in advance are introduced. SIFT algorithm is used to extract the features of the weak characteristic images in the overlapping areas, and the change in principal distance is calculated by the offset of feature points. Finally, the corresponding mechanical structure is adjusted according to the change in the principal distance, and aerial remote sensing images with sufficient sharpness are obtained. In this experiment, we select the second dimension with insufficient sharpness and the previous dimension with enough clear feature points in multiple groups of overlapping areas to verify the sharpness detection effect of the proposed algorithm between images with different sharpness (Fig. 5 and Fig. 6). In areas with abundant ground sceneries, 15 repeated experiments are carried out using different sharpness detection algorithms. The root-mean-square error of the sharpness detection parameters of the algorithm in this paper reaches 15.8 μm (Table 1). After 15 repeated experiments in areas with scarce ground sceneries, the root-mean-square error of the sharpness detection parameters of proposed algorithm can reach 16.3 μm. The classic sharpness detection algorithms such as Robert and proposed algorithm are used for weak characteristic areas, and 15 experiments are repeated. The sharpness detection curves are shown in Fig. 7. The root-mean-square error of sharpness detection parameters in the weak feature areas calculated by proposed algorithm can reach 16.275 μm (Table 2), and it meets the actual engineering accuracy requirements of aerial cameras. It is proved that proposed algorithm has a certain engineering application value.ConclusionsIn order to meet the application requirements of aerial cameras in military reconnaissance and topographic mapping, it is necessary to obtain clear aerial remote sensing images in real time. The key to obtaining a clear image is precise sharpness detection technology. In order to solve the problem of aerial camera imaging sharpness detection in weak characteristic areas, the characteristics of overlapping areas between the two images are analyzed, and a method of image sharpness detection of aerial cameras based on DEM is proposed. Based on DEM data, an aerial imaging model is optimized by minimizing the re-projection error. According to the geographical information of the sceneries in the overlapping areas of the aerial remote sensing images in the front and back formats, the change in the principal distance of the latter format relative to the previous format is calculated, so as to obtain the sharpness detection results. After many experiments, the root-mean-square error of sharpness measurement in areas with few features is 16.275 μm, which is within the range of half focal depth of an aerial camera optical system (19.2 μm). The accuracy meets the actual engineering accuracy requirements of aerial cameras, and the proposed algorithm has a certain engineering application value. ObjectiveThe working environment of aerial cameras is complex. In the process of acquiring aerial remote sensing images, the optical system is defocused due to the influence of external environments such as ground elevation difference, temperature, and air pressure. The obtained aerial remote sensing images are not clear enough. The sharpness detection methods based on image processing complete the sharpness detection through the spectrum analysis of high-frequency information in aerial remote sensing images. Taking advantage of the fast running speed of computers, the sharpness detection of aerial remote sensing images is completed in real time. Therefore, it has become the main method of sharpness detection both in China and abroad. However, the weak characteristic areas such as oceans, grasslands, and deserts, which cover more than half of the earth, have less high-frequency information in aerial remote sensing images. When using conventional image methods for sharpness detection, the error rate is high. According to the characteristics of overlapping areas between the two images, a method of aerial camera image sharpness detection based on a digital elevation model (DEM) is proposed. This method introduces a high-precision DEM, and according to the acquired weak characteristic areas, the two images before and after the aerial remote image sensing feature overlapping areas. The aerial imaging model is modified by minimizing the re-projection error, and the sharpness is detected according to the offset of feature points in the weak characteristic overlapping areas. It makes up for the defect that the sharpness detection methods based on image processing can't detect the sharpness in weak characteristic areas and expands the applicability of the sharpness detection methods based on image processing.MethodsIn this study, an aerial imaging model and feature point matching are used to obtain image sharpness parameters. Firstly, a DEM is used to provide the elevation data of the ground object in the aerial imaging model. The sum of the re-projection error of each pixel in the overlapping areas is regarded as the re-projection error function. By minimizing the re-projection error, relative error coefficients of various influencing factors can be obtained, so as to modify the aerial imaging model. Then, according to the characteristics of the overlapping areas between the two images, the geographical information of sceneries in the overlapping areas is regarded as public knowledge. The modified aerial imaging model is used to realize the feature point matching algorithm. In addition, according to the error between the feature matching points and the scale-invariant feature transformation (SIFT) algorithm matching points, the change in the azimuth elements in the aerial camera is calculated. Finally, the change in the principal distance is used as the sharpness detection result. Through the focal plane driving device of the aerial camera, the focal plane of the aerial camera can be quickly adjusted to an appropriate position, so as to obtain aerial remote sensing images with sufficient sharpness.Results and DiscussionsIn the experiment, aerial remote sensing images of the weak characteristic areas obtained by the aerial camera are transmitted to an image processing computer, and the DEM images with the accuracy of millimeter level processed by the computer in advance are introduced. SIFT algorithm is used to extract the features of the weak characteristic images in the overlapping areas, and the change in principal distance is calculated by the offset of feature points. Finally, the corresponding mechanical structure is adjusted according to the change in the principal distance, and aerial remote sensing images with sufficient sharpness are obtained. In this experiment, we select the second dimension with insufficient sharpness and the previous dimension with enough clear feature points in multiple groups of overlapping areas to verify the sharpness detection effect of the proposed algorithm between images with different sharpness (Fig. 5 and Fig. 6). In areas with abundant ground sceneries, 15 repeated experiments are carried out using different sharpness detection algorithms. The root-mean-square error of the sharpness detection parameters of the algorithm in this paper reaches 15.8 μm (Table 1). After 15 repeated experiments in areas with scarce ground sceneries, the root-mean-square error of the sharpness detection parameters of proposed algorithm can reach 16.3 μm. The classic sharpness detection algorithms such as Robert and proposed algorithm are used for weak characteristic areas, and 15 experiments are repeated. The sharpness detection curves are shown in Fig. 7. The root-mean-square error of sharpness detection parameters in the weak feature areas calculated by proposed algorithm can reach 16.275 μm (Table 2), and it meets the actual engineering accuracy requirements of aerial cameras. It is proved that proposed algorithm has a certain engineering application value.ConclusionsIn order to meet the application requirements of aerial cameras in military reconnaissance and topographic mapping, it is necessary to obtain clear aerial remote sensing images in real time. The key to obtaining a clear image is precise sharpness detection technology. In order to solve the problem of aerial camera imaging sharpness detection in weak characteristic areas, the characteristics of overlapping areas between the two images are analyzed, and a method of image sharpness detection of aerial cameras based on DEM is proposed. Based on DEM data, an aerial imaging model is optimized by minimizing the re-projection error. According to the geographical information of the sceneries in the overlapping areas of the aerial remote sensing images in the front and back formats, the change in the principal distance of the latter format relative to the previous format is calculated, so as to obtain the sharpness detection results. After many experiments, the root-mean-square error of sharpness measurement in areas with few features is 16.275 μm, which is within the range of half focal depth of an aerial camera optical system (19.2 μm). The accuracy meets the actual engineering accuracy requirements of aerial cameras, and the proposed algorithm has a certain engineering application value.
Acta Optica Sinica
- Publication Date: Mar. 25, 2023
- Vol. 43, Issue 6, 0610001 (2023)
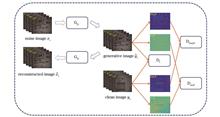
Polarization Image Denoising Based on Unsupervised Learning
Haofeng Hu, Huifeng Jin, Xiaobo Li, Jingsheng Zhai, and Tiegen Liu
ObjectiveThe imaging process of polarization images in the natural environment is easily affected by noise, which not only causes the acquired relevant polarimetric parameters to deviate from their real values but also affects the further processing of subsequent polarization information. Due to nonlinear operations, polarimetric parameters such as the degree of polarization (DoP) and the angle of polarization (AoP) are easily distorted by noise, especially in photon-starved environments. Therefore, effective denoising is crucial to polarimetric imaging. The denoising method based on deep learning can significantly remove the influence of noise on polarization images. However, the performance of current supervised algorithms is highly dependent on the labeled dataset, and high-quality polarization labels are difficult to obtain in practical applications, which limits the application of the existing methods. Therefore, this paper proposes a polarization image denoising method based on unsupervised learning. This method breaks the restriction that supervised learning-based deep learning requires strictly paired images and uses unpaired polarization images to train a polarization-specialized cycle generative adversarial network (CycleGan). The method in this paper are of great significance to the application of polarimetric imaging in complex noise environments.MethodsIn the proposed CycleGan structure, the discriminator for the input domain is removed, and two discriminators for polarimetric parameters are added. In the structure of generators, the residual dense block (RDB) is introduced to extract abundant local features via densely connected convolutional layers, and PatchGANs are adopted for discriminators, which can work on arbitrarily sized images and grow the receptive field after each convolution layer. In addition, a batch normalization (BN) layer and a ReLU layer are added right after each convolutional layer to accelerate network training. Furthermore, a cycle consistency loss is maintained to keep the consistency between input and output, and two cycle gradient losses are introduced for the degree of linear polarization (DoLP) and AoP to preserve the variations of polarization information. With the help of the designed network structure and the polarization-based loss function, the network trained by unpaired polarization images can statistically learn the mapping between noisy and clean images.Results and DiscussionsExperiments show that the network can effectively suppress the noise of polarization images in different indoor and outdoor environments and recover DoLP and AoP. The ablation experiment proves the effectiveness of additional polarization discriminators. With two discriminators, the network accurately recovers both DoLP and AoP images (Fig. 3) and achieves the highest PSNR/SSIM value among different network structures (Table 1). Compared with other methods, the unsupervised method has the best performance in terms of intensity, DoLP, and AoP images (Fig. 4). The average PSNR and SSIM of indoor images illustrate that the method has advantages in the reconstruction of DoLP images (Table 2). Several groups of experiments on different materials, including resin, fabric, wood, and plastic, are conducted to verify the universality of the proposed method. The denoised results reveal that the proposed method can suppress the noise of these materials for polarization information (Fig. 5). Finally, experiments with outdoor noise polarization images are carried out to verify the robustness of the method. Compared to the supervised method, the unsupervised method does not see dramatical performance degradation when applied to different environments (Fig. 6), which is important for the application of polarization imaging in realistic environments.ConclusionsThis paper proposes a polarization image denoising method based on unsupervised learning. On the basis of the CycleGan model, a structure of generative adversarial network suitable for polarization image denoising is designed. Through an unsupervised training network with unpaired images, a denoising network model that can effectively remove the noise of polarization images and restore polarization information is obtained. Experiments with indoor images are conducted to test the method, and qualitative and quantitative evaluations are given. The experimental results show that this method can achieve the same performance as the supervised learning method in indoor image denoising and can effectively restore polarization information, especially in DoLP image restoration. Furthermore, the polarization images of different materials are tested. The results reveal that this method has good generalization and can effectively recover the polarization information of different materials. In addition, the outdoor images are also tested, and a qualitative evaluation is presented. The experimental results suggest that this method can effectively remove the noise of indoor and outdoor images and restore real polarization information when indoor images are used as the training set. The models and methods proposed in this study can be extended to other applications. For example, they can be used to study polarization image denoising and polarization information recovery in extreme environments (e.g., night, low light). ObjectiveThe imaging process of polarization images in the natural environment is easily affected by noise, which not only causes the acquired relevant polarimetric parameters to deviate from their real values but also affects the further processing of subsequent polarization information. Due to nonlinear operations, polarimetric parameters such as the degree of polarization (DoP) and the angle of polarization (AoP) are easily distorted by noise, especially in photon-starved environments. Therefore, effective denoising is crucial to polarimetric imaging. The denoising method based on deep learning can significantly remove the influence of noise on polarization images. However, the performance of current supervised algorithms is highly dependent on the labeled dataset, and high-quality polarization labels are difficult to obtain in practical applications, which limits the application of the existing methods. Therefore, this paper proposes a polarization image denoising method based on unsupervised learning. This method breaks the restriction that supervised learning-based deep learning requires strictly paired images and uses unpaired polarization images to train a polarization-specialized cycle generative adversarial network (CycleGan). The method in this paper are of great significance to the application of polarimetric imaging in complex noise environments.MethodsIn the proposed CycleGan structure, the discriminator for the input domain is removed, and two discriminators for polarimetric parameters are added. In the structure of generators, the residual dense block (RDB) is introduced to extract abundant local features via densely connected convolutional layers, and PatchGANs are adopted for discriminators, which can work on arbitrarily sized images and grow the receptive field after each convolution layer. In addition, a batch normalization (BN) layer and a ReLU layer are added right after each convolutional layer to accelerate network training. Furthermore, a cycle consistency loss is maintained to keep the consistency between input and output, and two cycle gradient losses are introduced for the degree of linear polarization (DoLP) and AoP to preserve the variations of polarization information. With the help of the designed network structure and the polarization-based loss function, the network trained by unpaired polarization images can statistically learn the mapping between noisy and clean images.Results and DiscussionsExperiments show that the network can effectively suppress the noise of polarization images in different indoor and outdoor environments and recover DoLP and AoP. The ablation experiment proves the effectiveness of additional polarization discriminators. With two discriminators, the network accurately recovers both DoLP and AoP images (Fig. 3) and achieves the highest PSNR/SSIM value among different network structures (Table 1). Compared with other methods, the unsupervised method has the best performance in terms of intensity, DoLP, and AoP images (Fig. 4). The average PSNR and SSIM of indoor images illustrate that the method has advantages in the reconstruction of DoLP images (Table 2). Several groups of experiments on different materials, including resin, fabric, wood, and plastic, are conducted to verify the universality of the proposed method. The denoised results reveal that the proposed method can suppress the noise of these materials for polarization information (Fig. 5). Finally, experiments with outdoor noise polarization images are carried out to verify the robustness of the method. Compared to the supervised method, the unsupervised method does not see dramatical performance degradation when applied to different environments (Fig. 6), which is important for the application of polarization imaging in realistic environments.ConclusionsThis paper proposes a polarization image denoising method based on unsupervised learning. On the basis of the CycleGan model, a structure of generative adversarial network suitable for polarization image denoising is designed. Through an unsupervised training network with unpaired images, a denoising network model that can effectively remove the noise of polarization images and restore polarization information is obtained. Experiments with indoor images are conducted to test the method, and qualitative and quantitative evaluations are given. The experimental results show that this method can achieve the same performance as the supervised learning method in indoor image denoising and can effectively restore polarization information, especially in DoLP image restoration. Furthermore, the polarization images of different materials are tested. The results reveal that this method has good generalization and can effectively recover the polarization information of different materials. In addition, the outdoor images are also tested, and a qualitative evaluation is presented. The experimental results suggest that this method can effectively remove the noise of indoor and outdoor images and restore real polarization information when indoor images are used as the training set. The models and methods proposed in this study can be extended to other applications. For example, they can be used to study polarization image denoising and polarization information recovery in extreme environments (e.g., night, low light).
Acta Optica Sinica
- Publication Date: Feb. 25, 2023
- Vol. 43, Issue 4, 0410001 (2023)

A Robust Feature Matching Method for Wide-Baseline Lunar Images
Qihao Peng, Tengqi Zhao, Chuankai Liu, and Zhiyu Xiang
ObjectiveThe vision-based navigation and localization system of China's "Yutu" lunar rover is controlled by a ground teleoperation center. A large-spacing traveling mode with approximately 6-10 m per site is adopted for the rover to maximize the driving distance of the lunar rover and improve the efficiency of remote control exploration. This results in a significant distance between adjacent navigation sites, and considerable rotation, translation, and scale changes in the captured images. Furthermore, the low overlap between images and the vast differences in regional shapes, combined with weak texture and illumination variations on the lunar surface, pose challenges to image feature matching among different sites. Currently, the "Yutu" lunar rover employs inertial measurements and visual matches among different sites for navigation and positioning. The ground teleoperation center adopts inertial measurements as initial poses and optimizes the poses with visual matches by bundle adjustment to obtain the final rover poses. However, due to the wide baseline and significant surface changes of images at different sites, manual assistance is often required to filter or select the correct matches, significantly affecting the efficiency of the ground teleoperation center. Therefore, improving the robustness of image feature matching between different sites to achieve automatic visual positioning is an urgent problem to be addressed.MethodsTo address the poor performance and low success rate of current image matching algorithms in wide-baseline lunar images with weak textures and illumination variations, we propose a global attention-based lunar image matching algorithm by the view synthesis. First, we utilize sparse feature matching methods to generate sparse pseudo-ground-truth disparities for the rectified stereo lunar images at the same site. Next, we finetune a stereo matching network with these disparities and perform 3D reconstruction for the lunar images at the same site. Then, we leverage inertial measurements among different sites to convert the original image into a new synthetic view for matching based on the scene depth, addressing the low overlap and large viewpoint changes among images of different sites. Additionally, we adopt a Transformer-based image matching network to improve matching performance in weak-texture scenes, and an outlier rejection method that considers plane degeneration in the post-processing stage. Finally, the matches are returned from the synthetic image to the original image, yielding the matches for wide-baseline lunar images at different sites.Results and DiscussionsWe conduct experiments on the real lunar dataset from the "Yutu 2" lunar rover (referred to as the Moon dataset), which includes two parts. The first part is stereo images from five continuous stations (employed for stereo reconstruction), and the second is 12 sets of wide-baseline lunar images from adjacent sites (for wide-baseline image matching testing). In terms of lunar 3D reconstruction, we calculate the reconstruction error within different distance ranges, where the reconstruction network GwcNet (Moon) yields the best reconstruction accuracy and reconstruction details, as shown in Table 1 and Fig. 4. Meanwhile, Fig. 5 illustrates the synthetic images obtained from the view synthesis scheme based on the inertial measurements between sites and the scene depth, which solves the large rotation, translation, and scale changes between adjacent sites. For wide-baseline image matching, existing algorithms such as LoFTR and ASIFT have matching success rates of 33.33% and 16.67% respectively as shown in Table 2. Our DepthWarp-LoFTR algorithm achieves a matching success rate of 83.33%, significantly improving the matching success rate and accuracy of wide-baseline lunar images (Table 3). Additionally, this algorithm increases the matching success rate from 16.67% to 41.67% compared to the ASIFT algorithm. We present the matching results of different algorithms in Fig. 7, where DepthWarp-LoFTR obtains more consistent and denser matching results compared to other methods.ConclusionsWe propose a robust feature matching method DepthWarp-LoFTR for wide-baseline lunar images. For stereo images captured at the same site, the sparse disparities are generated through a sparse feature matching algorithm. These disparities serve as pseudo-ground truth to train the GwcNet network for 3D reconstruction of lunar images at the same site. To handle the wide baseline and low overlap of images from different sites, we propose a view synthesis algorithm based on scene depth and inertial prior poses. Image matching is performed on the synthesized current-site image and the next-site image to reduce the feature matching difficulty. For the feature matching stage, we adopt a Transformer-based LoFTR network, which significantly improves the success rate and accuracy of automatic matching. Our experimental results on real lunar datasets demonstrate that the proposed algorithm greatly improves the success rate of feature matching in complex lunar wide-baseline scenes. This lays a solid foundation for automatic visual positioning of the "Yutu 2" lunar rover and subsequent routine patrols of lunar rovers in China's fourth lunar exploration phase. ObjectiveThe vision-based navigation and localization system of China's "Yutu" lunar rover is controlled by a ground teleoperation center. A large-spacing traveling mode with approximately 6-10 m per site is adopted for the rover to maximize the driving distance of the lunar rover and improve the efficiency of remote control exploration. This results in a significant distance between adjacent navigation sites, and considerable rotation, translation, and scale changes in the captured images. Furthermore, the low overlap between images and the vast differences in regional shapes, combined with weak texture and illumination variations on the lunar surface, pose challenges to image feature matching among different sites. Currently, the "Yutu" lunar rover employs inertial measurements and visual matches among different sites for navigation and positioning. The ground teleoperation center adopts inertial measurements as initial poses and optimizes the poses with visual matches by bundle adjustment to obtain the final rover poses. However, due to the wide baseline and significant surface changes of images at different sites, manual assistance is often required to filter or select the correct matches, significantly affecting the efficiency of the ground teleoperation center. Therefore, improving the robustness of image feature matching between different sites to achieve automatic visual positioning is an urgent problem to be addressed.MethodsTo address the poor performance and low success rate of current image matching algorithms in wide-baseline lunar images with weak textures and illumination variations, we propose a global attention-based lunar image matching algorithm by the view synthesis. First, we utilize sparse feature matching methods to generate sparse pseudo-ground-truth disparities for the rectified stereo lunar images at the same site. Next, we finetune a stereo matching network with these disparities and perform 3D reconstruction for the lunar images at the same site. Then, we leverage inertial measurements among different sites to convert the original image into a new synthetic view for matching based on the scene depth, addressing the low overlap and large viewpoint changes among images of different sites. Additionally, we adopt a Transformer-based image matching network to improve matching performance in weak-texture scenes, and an outlier rejection method that considers plane degeneration in the post-processing stage. Finally, the matches are returned from the synthetic image to the original image, yielding the matches for wide-baseline lunar images at different sites.Results and DiscussionsWe conduct experiments on the real lunar dataset from the "Yutu 2" lunar rover (referred to as the Moon dataset), which includes two parts. The first part is stereo images from five continuous stations (employed for stereo reconstruction), and the second is 12 sets of wide-baseline lunar images from adjacent sites (for wide-baseline image matching testing). In terms of lunar 3D reconstruction, we calculate the reconstruction error within different distance ranges, where the reconstruction network GwcNet (Moon) yields the best reconstruction accuracy and reconstruction details, as shown in Table 1 and Fig. 4. Meanwhile, Fig. 5 illustrates the synthetic images obtained from the view synthesis scheme based on the inertial measurements between sites and the scene depth, which solves the large rotation, translation, and scale changes between adjacent sites. For wide-baseline image matching, existing algorithms such as LoFTR and ASIFT have matching success rates of 33.33% and 16.67% respectively as shown in Table 2. Our DepthWarp-LoFTR algorithm achieves a matching success rate of 83.33%, significantly improving the matching success rate and accuracy of wide-baseline lunar images (Table 3). Additionally, this algorithm increases the matching success rate from 16.67% to 41.67% compared to the ASIFT algorithm. We present the matching results of different algorithms in Fig. 7, where DepthWarp-LoFTR obtains more consistent and denser matching results compared to other methods.ConclusionsWe propose a robust feature matching method DepthWarp-LoFTR for wide-baseline lunar images. For stereo images captured at the same site, the sparse disparities are generated through a sparse feature matching algorithm. These disparities serve as pseudo-ground truth to train the GwcNet network for 3D reconstruction of lunar images at the same site. To handle the wide baseline and low overlap of images from different sites, we propose a view synthesis algorithm based on scene depth and inertial prior poses. Image matching is performed on the synthesized current-site image and the next-site image to reduce the feature matching difficulty. For the feature matching stage, we adopt a Transformer-based LoFTR network, which significantly improves the success rate and accuracy of automatic matching. Our experimental results on real lunar datasets demonstrate that the proposed algorithm greatly improves the success rate of feature matching in complex lunar wide-baseline scenes. This lays a solid foundation for automatic visual positioning of the "Yutu 2" lunar rover and subsequent routine patrols of lunar rovers in China's fourth lunar exploration phase.
Acta Optica Sinica
- Publication Date: Dec. 25, 2023
- Vol. 43, Issue 24, 2410001 (2023)
Efficient Dispersion Compensation Method Based on Spatial Pulse Width
Yushuai Xu, Huaiyu Cai, Lutong Wang, Yi Wang, and Xiaodong Chen
ObjectiveOptical coherence tomography (OCT) is a pivotal biomedical imaging technique based on the low coherence interference principle. It facilitates the production of tomographic scans of biological tissues, extensively applied to medical fields such as ophthalmology and dermatology. However, the pursuit of heightened axial resolution compels OCT systems to harness broadband light sources, and it is an approach that inadvertently introduces dispersion effects and gives rise to imaging artifacts, blurring, and consequently diminished image quality. Therefore, it is necessary to conduct dispersion compensation in OCT systems. While hardware-based compensation techniques are plagued by increased costs and complexity, their efficacy remains limited, which spurs the exploration and application of more flexible dispersion compensation algorithms. However, commonly employed algorithms based on search strategies suffer from suboptimal adaptability and concealed computational intricacies. Thus, we introduce an innovative dispersion compensation algorithm established based on the concept of spatial pulse degradation resulting from dispersion. The algorithm integrated into frequency domain OCT system experiments eliminates the requirements for manual dispersion range adjustments. Meanwhile, it features notable computational efficiency to offset the shortcomings of conventional search strategies in adaptability and computational efficacy. The proposed method is proven to be instrumental in enhancing the engineering practicality of OCT systems and improving the quality of tomographic images.MethodsWe propose an efficient dispersion compensation algorithm grounded in spatial pulse degradation due to dispersion and apply it to frequency domain OCT system experiments. The algorithm consists of two parts including dispersion extraction and compensation. By adopting the principle that dispersion causes widening spatial pulse, the algorithm estimates the dispersion of the signal to be corrected and subsequently applies compensation. A linear equation establishes the relationship between the square of spatial pulse width and the square of second-order dispersion. Additional dispersion phases are generated numerically and integrated into the original spectral signal to yield new dispersion signals. After transformation to the spatial domain, these signals' spatial pulse widths are measured. By substituting these pulse width values into the equation set, the second-order dispersion of the original signal can be calculated. Finally, a dispersion compensation phase is constructed and incorporated into the original spectral signal's phase for dispersion correction.Results and DiscussionsTo validate the efficacy of this algorithm, we devise a swept source OCT (SS-OCT) system for data collection. The method is applied to correct dispersion in the point spread function (PSF) of the system and biological tissue images. The experimental results show that the algorithm's dispersion estimates exhibit a relative error of less than 10% when compared to actual dispersion values in different dispersion conditions (Table 1). After implementing this algorithm for dispersion compensation, notable enhancements are observed in the system's peak signal-to-noise ratio and axial resolution. In scenarios of similar correction efficiency, this algorithm surpasses the commonly employed iterative method by a factor of 5 in terms of speed and outpaces the fractional Fourier transform method by a remarkable 50-fold (Table 2). Furthermore, after applying dispersion compensation, the image quality is notably improved. The grape flesh image boundaries exhibit enhanced sharpness, with significantly enhanced internal tissue clarity and more concentrated image energy (Fig. 4). Additionally, human retinal images display clearer layer differentiation, accompanied by image contrast improvement (Fig. 5). These results collectively prove the algorithm's efficacy in enhancing image quality.ConclusionsWe introduce a novel high-efficiency dispersion compensation algorithm grounded in spatial pulse width. The algorithm mitigates axial broadening in PSF and enhances the system's signal-to-noise ratio. Notably, the algorithm's strength lies in its independence from prior knowledge about system dispersion or manual dispersion search interval selection. It accurately estimates system dispersion, and when compared with other search strategy-based algorithms, it demonstrates superior computing efficiency and achieves comparable compensation efficacy. The dispersion compensation experiments conducted on grape pulp and human retinal images yield effective results. The algorithm suppresses axial broadening blur, amplifies image contrast, and elucidates intricate structural features within biological tissues. These outcomes underscore the algorithm's capacity to proficiently rectify dispersion issues in OCT systems, thereby enhancing visual image quality. Nevertheless, certain limitations deserve consideration. Primarily, the algorithm's applicability is confined to addressing second-order dispersion, and higher-order dispersion tackling necessitates further exploration into the numerical relationship between spatial pulse distortion and higher-order dispersion. Furthermore, the algorithm exclusively addresses system dispersion, ignoring sample dispersion intricacies tied to specific sample structures and depths. Future research should explore depth-adaptive sample dispersion compensation, and leverage the algorithm's high computational efficiency to potentially enable depth-dependent dispersion compensation. ObjectiveOptical coherence tomography (OCT) is a pivotal biomedical imaging technique based on the low coherence interference principle. It facilitates the production of tomographic scans of biological tissues, extensively applied to medical fields such as ophthalmology and dermatology. However, the pursuit of heightened axial resolution compels OCT systems to harness broadband light sources, and it is an approach that inadvertently introduces dispersion effects and gives rise to imaging artifacts, blurring, and consequently diminished image quality. Therefore, it is necessary to conduct dispersion compensation in OCT systems. While hardware-based compensation techniques are plagued by increased costs and complexity, their efficacy remains limited, which spurs the exploration and application of more flexible dispersion compensation algorithms. However, commonly employed algorithms based on search strategies suffer from suboptimal adaptability and concealed computational intricacies. Thus, we introduce an innovative dispersion compensation algorithm established based on the concept of spatial pulse degradation resulting from dispersion. The algorithm integrated into frequency domain OCT system experiments eliminates the requirements for manual dispersion range adjustments. Meanwhile, it features notable computational efficiency to offset the shortcomings of conventional search strategies in adaptability and computational efficacy. The proposed method is proven to be instrumental in enhancing the engineering practicality of OCT systems and improving the quality of tomographic images.MethodsWe propose an efficient dispersion compensation algorithm grounded in spatial pulse degradation due to dispersion and apply it to frequency domain OCT system experiments. The algorithm consists of two parts including dispersion extraction and compensation. By adopting the principle that dispersion causes widening spatial pulse, the algorithm estimates the dispersion of the signal to be corrected and subsequently applies compensation. A linear equation establishes the relationship between the square of spatial pulse width and the square of second-order dispersion. Additional dispersion phases are generated numerically and integrated into the original spectral signal to yield new dispersion signals. After transformation to the spatial domain, these signals' spatial pulse widths are measured. By substituting these pulse width values into the equation set, the second-order dispersion of the original signal can be calculated. Finally, a dispersion compensation phase is constructed and incorporated into the original spectral signal's phase for dispersion correction.Results and DiscussionsTo validate the efficacy of this algorithm, we devise a swept source OCT (SS-OCT) system for data collection. The method is applied to correct dispersion in the point spread function (PSF) of the system and biological tissue images. The experimental results show that the algorithm's dispersion estimates exhibit a relative error of less than 10% when compared to actual dispersion values in different dispersion conditions (Table 1). After implementing this algorithm for dispersion compensation, notable enhancements are observed in the system's peak signal-to-noise ratio and axial resolution. In scenarios of similar correction efficiency, this algorithm surpasses the commonly employed iterative method by a factor of 5 in terms of speed and outpaces the fractional Fourier transform method by a remarkable 50-fold (Table 2). Furthermore, after applying dispersion compensation, the image quality is notably improved. The grape flesh image boundaries exhibit enhanced sharpness, with significantly enhanced internal tissue clarity and more concentrated image energy (Fig. 4). Additionally, human retinal images display clearer layer differentiation, accompanied by image contrast improvement (Fig. 5). These results collectively prove the algorithm's efficacy in enhancing image quality.ConclusionsWe introduce a novel high-efficiency dispersion compensation algorithm grounded in spatial pulse width. The algorithm mitigates axial broadening in PSF and enhances the system's signal-to-noise ratio. Notably, the algorithm's strength lies in its independence from prior knowledge about system dispersion or manual dispersion search interval selection. It accurately estimates system dispersion, and when compared with other search strategy-based algorithms, it demonstrates superior computing efficiency and achieves comparable compensation efficacy. The dispersion compensation experiments conducted on grape pulp and human retinal images yield effective results. The algorithm suppresses axial broadening blur, amplifies image contrast, and elucidates intricate structural features within biological tissues. These outcomes underscore the algorithm's capacity to proficiently rectify dispersion issues in OCT systems, thereby enhancing visual image quality. Nevertheless, certain limitations deserve consideration. Primarily, the algorithm's applicability is confined to addressing second-order dispersion, and higher-order dispersion tackling necessitates further exploration into the numerical relationship between spatial pulse distortion and higher-order dispersion. Furthermore, the algorithm exclusively addresses system dispersion, ignoring sample dispersion intricacies tied to specific sample structures and depths. Future research should explore depth-adaptive sample dispersion compensation, and leverage the algorithm's high computational efficiency to potentially enable depth-dependent dispersion compensation.
Acta Optica Sinica
- Publication Date: Dec. 10, 2023
- Vol. 43, Issue 23, 2310001 (2023)
Fast Image Matching Based on Channel Attention and Feature Slicing
Shaoyan Gai, Yanyan Huang, and Feipeng Da
ObjectiveImage matching is the process of finding spatial alignment relationships between identical or similar target objects in multiple images. Image matching is one of the research hotspots in the field of optical measurement, which is widely used in image mosaic, product optical measurement, video anti-shake, iterative reconstruction, and other fields. In current research work, accelerating image matching mainly starts from two aspects: accelerating feature point detection speed and accelerating feature matching speed. The most representative method for accelerating feature point detection is the oriented fast and rotated brief (ORB) operator, which detects feature points by comparing the pixel differences between different points. The operation process is relatively simple, and the processing speed is fast. In addition, some algorithms speed up image matching by filtering feature points. Some algorithms reduce image matching time by accelerating the speed of feature matching. Ye et al. designed a compact discriminative binary descriptor (CDbin) to obtain binary feature descriptors with smaller number of training parameters. The existing image matching algorithms tend to focus on matching accuracy while neglecting the decrease in matching speed to some extent. In order to solve this problem, an algorithm is proposed, which outperforms most other binary matching algorithms in terms of matching performance and time.MethodsThe floating-point feature descriptors output by the feature description algorithm are converted into binary feature descriptors to reduce the computational complexity during feature matching and thus reduce feature matching time. This article is inspired by the classical methods. Gu et al. modified the AlexNet structure based on the depth convolutional neural network and mapped the output descriptive sub element value to -1 or 1. Yang et al. used multi-bit binary descriptors to describe image blocks, reducing information loss caused by directly converting real-valued floating-point descriptors into binary descriptors. Soleimani et al. proposed a cyclic shift binary descriptor, which reduced the number of parameters used for calculating descriptors and thus improved matching speed. This article is inspired by the feature representation deep neural network SFLHC, which uses Sigmoid functions and segmented threshold functions separately for each element, binarizes them, and combines the idea of channel attention to improve the binary feature description network. A channel attention and feature slicing description network (CAFSD) is designed, which is combined with the fast feature point detection algorithm, namely ORB. Furthermore, a fast image matching algorithm based on channel attention mechanism and feature slicing is proposed, which can significantly improve the matching speed of images while improving the accuracy of binary description. In addition, based on the triplet loss function, the quantization loss function, uniform distribution loss function, and correlation loss function are introduced to form a composite loss function to optimize network training, further reducing the error of converting floating point descriptors to binary descriptors.Results and DiscussionsThe core CAFSD feature description network of this algorithm is trained and tested using the UBC Phototour dataset. The UBC Phototour dataset includes three sub datasets: Liberty, NotreDame, and Yosemite. Usually, one dataset is used to train the network, while the other two datasets are used to test the network, and the average value is taken as the final result. In addition, for the testing of the entire image matching algorithm (Fig. 1), 20 circuit board data are used. Commonly used evaluation indicators include FPR95, matching accuracy, matching score, and matching time. FPR95 is an evaluation indicator used in the UBC Phototour dataset to measure the quality of feature description algorithms. Other indicators are used for the overall testing of image matching algorithms, where matching time refers to the time taken by the algorithm from feature detection to the end of feature matching. The results are shown in Table 1. Loss functions of LT and LQ, LT and LE, as well as LT and LC are used to participate in CAFSD training, and UBC Phototour dataset is used for testing. The optimal coefficients for LQ, LE, and LC results are 1, 0.5, and 0.5. In combination with the ORB detection algorithm, the CAFSD has been developed. It can be seen that the speed and accuracy of matching images can be improved obviously.ConclusionsThis article proposes a fast image matching algorithm based on channel attention and feature slicing, with the core of the algorithm being CAFSD. Compact discriminative binary descriptor obtains binary feature descriptors with smaller number of training parameters. The existing image matching algorithms tend to focus on matching accuracy while neglecting the decrease in matching speed to some extent. In order to solve this problem, the CAFSD algorithm is proposed in this article. The inspiration for this article comes from the special power of the SFLHC deep neural network, which uses binary Sigmoid functions and piecewise finite functions for each element and combines the idea of channel focusing to improve the binary part network for complex recognition of binary scenes. In combination with the ORB detection algorithm, the CAFSD has been developed. In addition, based on channel attention and additional offloading, a fast image algorithm has been presented and proved. ObjectiveImage matching is the process of finding spatial alignment relationships between identical or similar target objects in multiple images. Image matching is one of the research hotspots in the field of optical measurement, which is widely used in image mosaic, product optical measurement, video anti-shake, iterative reconstruction, and other fields. In current research work, accelerating image matching mainly starts from two aspects: accelerating feature point detection speed and accelerating feature matching speed. The most representative method for accelerating feature point detection is the oriented fast and rotated brief (ORB) operator, which detects feature points by comparing the pixel differences between different points. The operation process is relatively simple, and the processing speed is fast. In addition, some algorithms speed up image matching by filtering feature points. Some algorithms reduce image matching time by accelerating the speed of feature matching. Ye et al. designed a compact discriminative binary descriptor (CDbin) to obtain binary feature descriptors with smaller number of training parameters. The existing image matching algorithms tend to focus on matching accuracy while neglecting the decrease in matching speed to some extent. In order to solve this problem, an algorithm is proposed, which outperforms most other binary matching algorithms in terms of matching performance and time.MethodsThe floating-point feature descriptors output by the feature description algorithm are converted into binary feature descriptors to reduce the computational complexity during feature matching and thus reduce feature matching time. This article is inspired by the classical methods. Gu et al. modified the AlexNet structure based on the depth convolutional neural network and mapped the output descriptive sub element value to -1 or 1. Yang et al. used multi-bit binary descriptors to describe image blocks, reducing information loss caused by directly converting real-valued floating-point descriptors into binary descriptors. Soleimani et al. proposed a cyclic shift binary descriptor, which reduced the number of parameters used for calculating descriptors and thus improved matching speed. This article is inspired by the feature representation deep neural network SFLHC, which uses Sigmoid functions and segmented threshold functions separately for each element, binarizes them, and combines the idea of channel attention to improve the binary feature description network. A channel attention and feature slicing description network (CAFSD) is designed, which is combined with the fast feature point detection algorithm, namely ORB. Furthermore, a fast image matching algorithm based on channel attention mechanism and feature slicing is proposed, which can significantly improve the matching speed of images while improving the accuracy of binary description. In addition, based on the triplet loss function, the quantization loss function, uniform distribution loss function, and correlation loss function are introduced to form a composite loss function to optimize network training, further reducing the error of converting floating point descriptors to binary descriptors.Results and DiscussionsThe core CAFSD feature description network of this algorithm is trained and tested using the UBC Phototour dataset. The UBC Phototour dataset includes three sub datasets: Liberty, NotreDame, and Yosemite. Usually, one dataset is used to train the network, while the other two datasets are used to test the network, and the average value is taken as the final result. In addition, for the testing of the entire image matching algorithm (Fig. 1), 20 circuit board data are used. Commonly used evaluation indicators include FPR95, matching accuracy, matching score, and matching time. FPR95 is an evaluation indicator used in the UBC Phototour dataset to measure the quality of feature description algorithms. Other indicators are used for the overall testing of image matching algorithms, where matching time refers to the time taken by the algorithm from feature detection to the end of feature matching. The results are shown in Table 1. Loss functions of LT and LQ, LT and LE, as well as LT and LC are used to participate in CAFSD training, and UBC Phototour dataset is used for testing. The optimal coefficients for LQ, LE, and LC results are 1, 0.5, and 0.5. In combination with the ORB detection algorithm, the CAFSD has been developed. It can be seen that the speed and accuracy of matching images can be improved obviously.ConclusionsThis article proposes a fast image matching algorithm based on channel attention and feature slicing, with the core of the algorithm being CAFSD. Compact discriminative binary descriptor obtains binary feature descriptors with smaller number of training parameters. The existing image matching algorithms tend to focus on matching accuracy while neglecting the decrease in matching speed to some extent. In order to solve this problem, the CAFSD algorithm is proposed in this article. The inspiration for this article comes from the special power of the SFLHC deep neural network, which uses binary Sigmoid functions and piecewise finite functions for each element and combines the idea of channel focusing to improve the binary part network for complex recognition of binary scenes. In combination with the ORB detection algorithm, the CAFSD has been developed. In addition, based on channel attention and additional offloading, a fast image algorithm has been presented and proved.
Acta Optica Sinica
- Publication Date: Nov. 25, 2023
- Vol. 43, Issue 22, 2210001 (2023)
Unsupervised Denoising of Retinal OCT Images Based on Deep Learning
Guangyi Wu, Zhuoqun Yuan, and Yanmei Liang
ObjectiveOptical coherence tomography (OCT) is employed as a safe and effective diagnostic tool for a variety of ophthalmic diseases due to its high resolution and non-invasive imaging, which is regarded as the "gold standard" in ophthalmic disease diagnosis. However, various kinds of noise, especially speckle noise, seriously affect the quality of retinal OCT images to reduce the contrast and resolution, which makes it difficult to segment and measure retinal sublayer thickness at the pixel level. Therefore, it is of significance to reduce the noise of retinal OCT images and retain structural details such as layering and edges of the images to the greatest extent. The deep learning-based noise reduction method shows advantages in image quality, especially in preserving edge details. However, for in vivo imaging, it is difficult to obtain a large number of multi-frame registration ground truth images, which affects the performance of the supervised learning method. Therefore, the realization of unsupervised denoising independent of ground truth images is vital in the clinical diagnosis of eye diseases.MethodsWe propose an unsupervised deep residual sparse attention network (DRSA-Net) based on the Noise2Noise training strategy for retinal OCT image denoising. DRSA-Net consists of local sparse attention block (LSAB), depth extraction block (DEB), global attention block (GAB), and residual block (RB). The TMI_2013OCT dataset publicly provided by Duke University is selected and preprocessed, and a total of 7800 Clean-Noisy and Noisy-Noisy image pairs are obtained. The proposed DRSA-Net is compared with the classical deep learning denoising networks U-Net and DnCNN from two aspects of qualitative visual evaluation and quantitative numerical evaluation and is also compared with the traditional BM3D algorithm. Then the denoising effects of three convolutional neural networks under supervised learning and unsupervised learning strategies are compared. Finally, generalization ability tests and network module ablation experiments are performed based on another public retinal OCT image dataset.Results and DiscussionsThe results of unsupervised training denoising (Fig. 3) show that the built model has better denoise and intra-layer fine structure preservation ability for retinal OCT images. U-Net-N2N tends to destroy the details and boundary of layers and introduces some fuzzy structures among layers. DnCNN-N2N brings degradation of layer boundary and blurring of the outer limiting membrane. The comparison between the results of supervised training and unsupervised training (Fig. 4) indicates that when ideal ground truth images cannot be provided, the denoised images of the supervised learning model have more noise, while the unsupervised learning model has a higher denoise degree and can provide clearer structures and edge information. The denoising numerical evaluation results of supervised learning and unsupervised learning (Table 1) show that compared with the original noise images, the supervised learning and unsupervised learning models realize great improvement in various evaluation indexes of the images. Additionally, compared with the traditional block matching algorithm BM3D, the denoising algorithm based on deep learning reduces the denoising time by two orders of magnitude. High-quality noise reduction of OCT images can be achieved within 1 s, and the proposed algorithm can get ahead of most evaluation indexes regardless of what kind of training strategy is adopted. The test results of generalization ability of unsupervised learning (Fig. 5) show that our proposed model has better generalization ability among different datasets, and can obtain a cleaner background than ground truth in terms of background denoise. In terms of structural information retention, it has clearer interlayer structures and more uniform layers. The results of ablation experiments on different modules of the denoising network proposed (Table 3) indicate that the combination of LSAB+DEB+GAB+RB is better in various evaluation indexes, which fully demonstrates the contribution of each module in the network structure to high-quality noise reduction.ConclusionsWe put forward an unsupervised depth residual sparse attention denoising algorithm independent of ground truth images to solve the noise interference in retinal OCT images and the difficulty of acquiring high-quality multi-frame average images in in vivo imaging. The attention mechanism is combined with sparse convolution kernel to complete the information mining between data efficiently and fully, and the Noise2Noise training strategy is adopted to complete the high-quality training with noise images, which achieves a high level of noise reduction and preserves the multi-layer structure information of retinal OCT images. The traditional denoising algorithm and the classical deep learning network are compared and analyzed from the visual evaluation and numerical evaluation including PSNR, SSIM, EPI, and ENL respectively. The denoising effect of supervised learning and unsupervised learning and the experimental results of the generalization ability test on the public retinal OCT image dataset show that the proposed noise reduction algorithm yields good results in various evaluation indexes and has strong generalization. Compared with supervised learning, unsupervised learning can still obtain better noise reduction performance under insufficient data sets. ObjectiveOptical coherence tomography (OCT) is employed as a safe and effective diagnostic tool for a variety of ophthalmic diseases due to its high resolution and non-invasive imaging, which is regarded as the "gold standard" in ophthalmic disease diagnosis. However, various kinds of noise, especially speckle noise, seriously affect the quality of retinal OCT images to reduce the contrast and resolution, which makes it difficult to segment and measure retinal sublayer thickness at the pixel level. Therefore, it is of significance to reduce the noise of retinal OCT images and retain structural details such as layering and edges of the images to the greatest extent. The deep learning-based noise reduction method shows advantages in image quality, especially in preserving edge details. However, for in vivo imaging, it is difficult to obtain a large number of multi-frame registration ground truth images, which affects the performance of the supervised learning method. Therefore, the realization of unsupervised denoising independent of ground truth images is vital in the clinical diagnosis of eye diseases.MethodsWe propose an unsupervised deep residual sparse attention network (DRSA-Net) based on the Noise2Noise training strategy for retinal OCT image denoising. DRSA-Net consists of local sparse attention block (LSAB), depth extraction block (DEB), global attention block (GAB), and residual block (RB). The TMI_2013OCT dataset publicly provided by Duke University is selected and preprocessed, and a total of 7800 Clean-Noisy and Noisy-Noisy image pairs are obtained. The proposed DRSA-Net is compared with the classical deep learning denoising networks U-Net and DnCNN from two aspects of qualitative visual evaluation and quantitative numerical evaluation and is also compared with the traditional BM3D algorithm. Then the denoising effects of three convolutional neural networks under supervised learning and unsupervised learning strategies are compared. Finally, generalization ability tests and network module ablation experiments are performed based on another public retinal OCT image dataset.Results and DiscussionsThe results of unsupervised training denoising (Fig. 3) show that the built model has better denoise and intra-layer fine structure preservation ability for retinal OCT images. U-Net-N2N tends to destroy the details and boundary of layers and introduces some fuzzy structures among layers. DnCNN-N2N brings degradation of layer boundary and blurring of the outer limiting membrane. The comparison between the results of supervised training and unsupervised training (Fig. 4) indicates that when ideal ground truth images cannot be provided, the denoised images of the supervised learning model have more noise, while the unsupervised learning model has a higher denoise degree and can provide clearer structures and edge information. The denoising numerical evaluation results of supervised learning and unsupervised learning (Table 1) show that compared with the original noise images, the supervised learning and unsupervised learning models realize great improvement in various evaluation indexes of the images. Additionally, compared with the traditional block matching algorithm BM3D, the denoising algorithm based on deep learning reduces the denoising time by two orders of magnitude. High-quality noise reduction of OCT images can be achieved within 1 s, and the proposed algorithm can get ahead of most evaluation indexes regardless of what kind of training strategy is adopted. The test results of generalization ability of unsupervised learning (Fig. 5) show that our proposed model has better generalization ability among different datasets, and can obtain a cleaner background than ground truth in terms of background denoise. In terms of structural information retention, it has clearer interlayer structures and more uniform layers. The results of ablation experiments on different modules of the denoising network proposed (Table 3) indicate that the combination of LSAB+DEB+GAB+RB is better in various evaluation indexes, which fully demonstrates the contribution of each module in the network structure to high-quality noise reduction.ConclusionsWe put forward an unsupervised depth residual sparse attention denoising algorithm independent of ground truth images to solve the noise interference in retinal OCT images and the difficulty of acquiring high-quality multi-frame average images in in vivo imaging. The attention mechanism is combined with sparse convolution kernel to complete the information mining between data efficiently and fully, and the Noise2Noise training strategy is adopted to complete the high-quality training with noise images, which achieves a high level of noise reduction and preserves the multi-layer structure information of retinal OCT images. The traditional denoising algorithm and the classical deep learning network are compared and analyzed from the visual evaluation and numerical evaluation including PSNR, SSIM, EPI, and ENL respectively. The denoising effect of supervised learning and unsupervised learning and the experimental results of the generalization ability test on the public retinal OCT image dataset show that the proposed noise reduction algorithm yields good results in various evaluation indexes and has strong generalization. Compared with supervised learning, unsupervised learning can still obtain better noise reduction performance under insufficient data sets.
Acta Optica Sinica
- Publication Date: Oct. 25, 2023
- Vol. 43, Issue 20, 2010002 (2023)
Depth Estimation Based on Spatial Geometry in Focal Stacks
Tianqi Luo, Xiaojuan Deng, Chang Liu, and Jun Qiu
ObjectiveDepth estimation is an important research topic in the field of computer vision, which is used to perceive and reconstruct three-dimensional (3D) scenes using two-dimensional (2D) images. Estimating depth based on a focal stack is a passive method that uses the degree of focus as a depth clue. This method has advantages including small imaging equipment size and low computational cost. However, this method relies heavily on the measurement of image focus, which is considerably affected by the texture information related to a scene. Measuring the degree of focus accurately in regions with poor lighting, smooth textures, or occlusions is difficult, leading to inaccurate depth estimation in these areas. Previous studies have proposed various optimization algorithms to increase the accuracy of depth estimation. These algorithms can generally be classified into three categories: designing satisfactory focus-measurement operators, optimizing the focus-measurement volume data to correct errors, and using all-in-focus images for guided filtering of the initial depth map. However, numerous factors, including scene texture, contrast, illumination, and window size, can affect the performance of focus-measurement operators, resulting in erroneous estimates in initial focus-measure volume data, resulting in inaccurate depth estimation. Effectiveness of the methods that optimize an initial depth map heavily depends on the accuracy of the initial depth map. Because the initial depth values may be estimated incorrectly owing to insufficient illumination, introducing considerably valid information to improve depth estimation through postprocessing is difficult. Therefore, intermediate optimization methods are ideal for improving the accuracy of a depth map. To solve the problem of inaccurate depth clues in regions showing weak texture and occlusion, this study proposes a novel method based on 3D adaptive-weighted total variation (TV) to optimize focus-measure volume data.MethodsThe proposed method consists of two key parts: 1) defining a structure consistency operator based on the prior geometric information related to different dimensions between the focal stack and focus-measure volume data, which is used to locate the depth boundary and area with high reliable depth clues to increase the accuracy of depth optimization; 2) incorporating the prior geometric information related to the scene hidden in the 3D focal stack and focus-measure volume data into the 3D TV regularization model. The structure of the image is measured using pixel-gradient values. Gradient jumps in the focal stack reflect changes in physical structure, while those in the focus-measure volume data reflect changes in focus level. When the physical structure and focus level exhibit considerable variations at the same position, the structure is consistent and corresponds to an area with reliable depth change. By measuring the structural consistency between the focal stack and focus measure, we can determine the positions exhibiting reliable depth clues and guide the optimization process related to the focus-measure data highly accurately. The traditional 2D TV optimization model has some edge-preserving ability while performing denoising. However, when the noise-gradient amplitude exceeds the edge-gradient amplitude, this model faces a dilemma between balancing denoising and preserving edge details. Based on the guided filtering method, the edge information of a reference image is used to denoise the target image, effectively resolving the dilemma. This leads to a weighted TV optimization model; however, when applying guided filtering to 2D images, the optimization information that can be introduced is limited. Therefore, we attempt to extend this method to a 3D image field. A weighted 3D TV regularization model can balance denoising and edge-preserving abilities high effectively owing to the rich information in 3D data. Herein, the process of optimizing the focus-measure data is modeled as a 3D weighted TV regularization method, and the adaptive weight is determined based on structural consistency.Results and DiscussionsFirst, an analysis is conducted on the selection of model parameters. We observe that adjusting these parameters can considerably impact the performance of the proposed algorithm, thereby optimizing the accuracy of depth estimation. Second, herein, a detailed analysis is conducted on the impact of structural consistency during the optimization process and the problems that may arise because of focusing solely on texture information for optimization. A comparative analysis is also performed with the introduction of 3D structural consistency. Finally, the proposed algorithm is tested on simulated and real image sequence datasets and the results are compared with those from two other methods: mutually guided image filtering (MuGIF) and robust focus volume (RFV). The proposed method computes 3D structural consistency, which is an additional dimension of information, as opposed to the MuGIF method, which uses consistent structural guidance filtering on inputs from all-in-focus and depth maps. The RFV method uses focal stacks to guide focus measure for optimizing depth estimation in 3D. Compared with the RFV method, the proposed method considers the property issues related to focal stack and focus measure and uses their consistent structure to guide optimization. Furthermore, three evaluation metrics are used to analyze and validate the three algorithms with respect to simulated data. The experimental results demonstrate that the proposed method exhibits better performance than the other methods, providing more accurate information for correcting the focusing measure process through 3D structural consistency. The proposed method not only preserves edge information but also preserves texture information with high accuracy and reduces errors in depth estimation.ConclusionsFocal stack contains physical color information of a scene, while focus measure contains textural and geometric structure information of the scene. In this study, we propose a method for measuring the structural consistency between the two to effectively locate the depth discontinuities. A structural consistency weighted TV model enhances the ability of the model to preserve edge information while avoiding the introduction of color information into a depth map. Thus, effectively addressing the problem of loss of depth clues related to focal-stack depth estimation in regions with weak texture and occlusion and increasing the accuracy of depth reconstruction. The computation of the L1 model of TV is relatively easy; however, this computation suffers from local distortion. Using highly advanced regularization terms may further improve the reconstruction effect. Future research needs to consider ways of incorporating increased data and investigating methods to improve the regularization term during the optimization process. ObjectiveDepth estimation is an important research topic in the field of computer vision, which is used to perceive and reconstruct three-dimensional (3D) scenes using two-dimensional (2D) images. Estimating depth based on a focal stack is a passive method that uses the degree of focus as a depth clue. This method has advantages including small imaging equipment size and low computational cost. However, this method relies heavily on the measurement of image focus, which is considerably affected by the texture information related to a scene. Measuring the degree of focus accurately in regions with poor lighting, smooth textures, or occlusions is difficult, leading to inaccurate depth estimation in these areas. Previous studies have proposed various optimization algorithms to increase the accuracy of depth estimation. These algorithms can generally be classified into three categories: designing satisfactory focus-measurement operators, optimizing the focus-measurement volume data to correct errors, and using all-in-focus images for guided filtering of the initial depth map. However, numerous factors, including scene texture, contrast, illumination, and window size, can affect the performance of focus-measurement operators, resulting in erroneous estimates in initial focus-measure volume data, resulting in inaccurate depth estimation. Effectiveness of the methods that optimize an initial depth map heavily depends on the accuracy of the initial depth map. Because the initial depth values may be estimated incorrectly owing to insufficient illumination, introducing considerably valid information to improve depth estimation through postprocessing is difficult. Therefore, intermediate optimization methods are ideal for improving the accuracy of a depth map. To solve the problem of inaccurate depth clues in regions showing weak texture and occlusion, this study proposes a novel method based on 3D adaptive-weighted total variation (TV) to optimize focus-measure volume data.MethodsThe proposed method consists of two key parts: 1) defining a structure consistency operator based on the prior geometric information related to different dimensions between the focal stack and focus-measure volume data, which is used to locate the depth boundary and area with high reliable depth clues to increase the accuracy of depth optimization; 2) incorporating the prior geometric information related to the scene hidden in the 3D focal stack and focus-measure volume data into the 3D TV regularization model. The structure of the image is measured using pixel-gradient values. Gradient jumps in the focal stack reflect changes in physical structure, while those in the focus-measure volume data reflect changes in focus level. When the physical structure and focus level exhibit considerable variations at the same position, the structure is consistent and corresponds to an area with reliable depth change. By measuring the structural consistency between the focal stack and focus measure, we can determine the positions exhibiting reliable depth clues and guide the optimization process related to the focus-measure data highly accurately. The traditional 2D TV optimization model has some edge-preserving ability while performing denoising. However, when the noise-gradient amplitude exceeds the edge-gradient amplitude, this model faces a dilemma between balancing denoising and preserving edge details. Based on the guided filtering method, the edge information of a reference image is used to denoise the target image, effectively resolving the dilemma. This leads to a weighted TV optimization model; however, when applying guided filtering to 2D images, the optimization information that can be introduced is limited. Therefore, we attempt to extend this method to a 3D image field. A weighted 3D TV regularization model can balance denoising and edge-preserving abilities high effectively owing to the rich information in 3D data. Herein, the process of optimizing the focus-measure data is modeled as a 3D weighted TV regularization method, and the adaptive weight is determined based on structural consistency.Results and DiscussionsFirst, an analysis is conducted on the selection of model parameters. We observe that adjusting these parameters can considerably impact the performance of the proposed algorithm, thereby optimizing the accuracy of depth estimation. Second, herein, a detailed analysis is conducted on the impact of structural consistency during the optimization process and the problems that may arise because of focusing solely on texture information for optimization. A comparative analysis is also performed with the introduction of 3D structural consistency. Finally, the proposed algorithm is tested on simulated and real image sequence datasets and the results are compared with those from two other methods: mutually guided image filtering (MuGIF) and robust focus volume (RFV). The proposed method computes 3D structural consistency, which is an additional dimension of information, as opposed to the MuGIF method, which uses consistent structural guidance filtering on inputs from all-in-focus and depth maps. The RFV method uses focal stacks to guide focus measure for optimizing depth estimation in 3D. Compared with the RFV method, the proposed method considers the property issues related to focal stack and focus measure and uses their consistent structure to guide optimization. Furthermore, three evaluation metrics are used to analyze and validate the three algorithms with respect to simulated data. The experimental results demonstrate that the proposed method exhibits better performance than the other methods, providing more accurate information for correcting the focusing measure process through 3D structural consistency. The proposed method not only preserves edge information but also preserves texture information with high accuracy and reduces errors in depth estimation.ConclusionsFocal stack contains physical color information of a scene, while focus measure contains textural and geometric structure information of the scene. In this study, we propose a method for measuring the structural consistency between the two to effectively locate the depth discontinuities. A structural consistency weighted TV model enhances the ability of the model to preserve edge information while avoiding the introduction of color information into a depth map. Thus, effectively addressing the problem of loss of depth clues related to focal-stack depth estimation in regions with weak texture and occlusion and increasing the accuracy of depth reconstruction. The computation of the L1 model of TV is relatively easy; however, this computation suffers from local distortion. Using highly advanced regularization terms may further improve the reconstruction effect. Future research needs to consider ways of incorporating increased data and investigating methods to improve the regularization term during the optimization process.
Acta Optica Sinica
- Publication Date: Oct. 25, 2023
- Vol. 43, Issue 20, 2010001 (2023)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20